ScalarLM Benchmarking MI300X BF16 GEMM
This blog covers the performance of the MI300X GPU in the context of a bfloat16 GEMM benchmark.
Here are the specs of the MI300X GPU for reference:
- BF16 Compute: 1.3 PFLOP/s
- FP8 Compute: 2.6 PFLOP/s
- HBM: 192GB HBM3E
- HBM Bandwidth: 5.3 TB/s
- Power Consumption: 750W
GEMM (General Matrix Multiply) is a fundamental operation in many machine learning and scientific computing applications, particularly in training and inference of large language models (LLMs). The MI300X GPU’s support for bfloat16 (BF16) precision allows for efficient computation while maintaining a balance between performance and numerical stability.
GEMM on MI300X
MI300X has a bfloat16 flops to memory ratio of 2.6 PFLOP/s / 5.3 TB/s = 490 flops/bytes. This means that for every byte of memory accessed, the MI300X needs to perform at least 490 floating point operations to achieve peak performance. In the context of a GEMM operation, this means that each matrix dimension should be at least 490. While training transformer LLMs, this ratio is typically achieved by batching over the sequence length. However, during inference using auto-regressive decoding when one token is generated per step, the sequence length is typically 1, which means that the batch size must be large enough (i.e. more than 490) to achieve the required flops to memory ratio. As we will see in the benchmark results, the compute to memory ratio typically needs to be even higher than 490 due to the overhead of the GEMM operation itself.
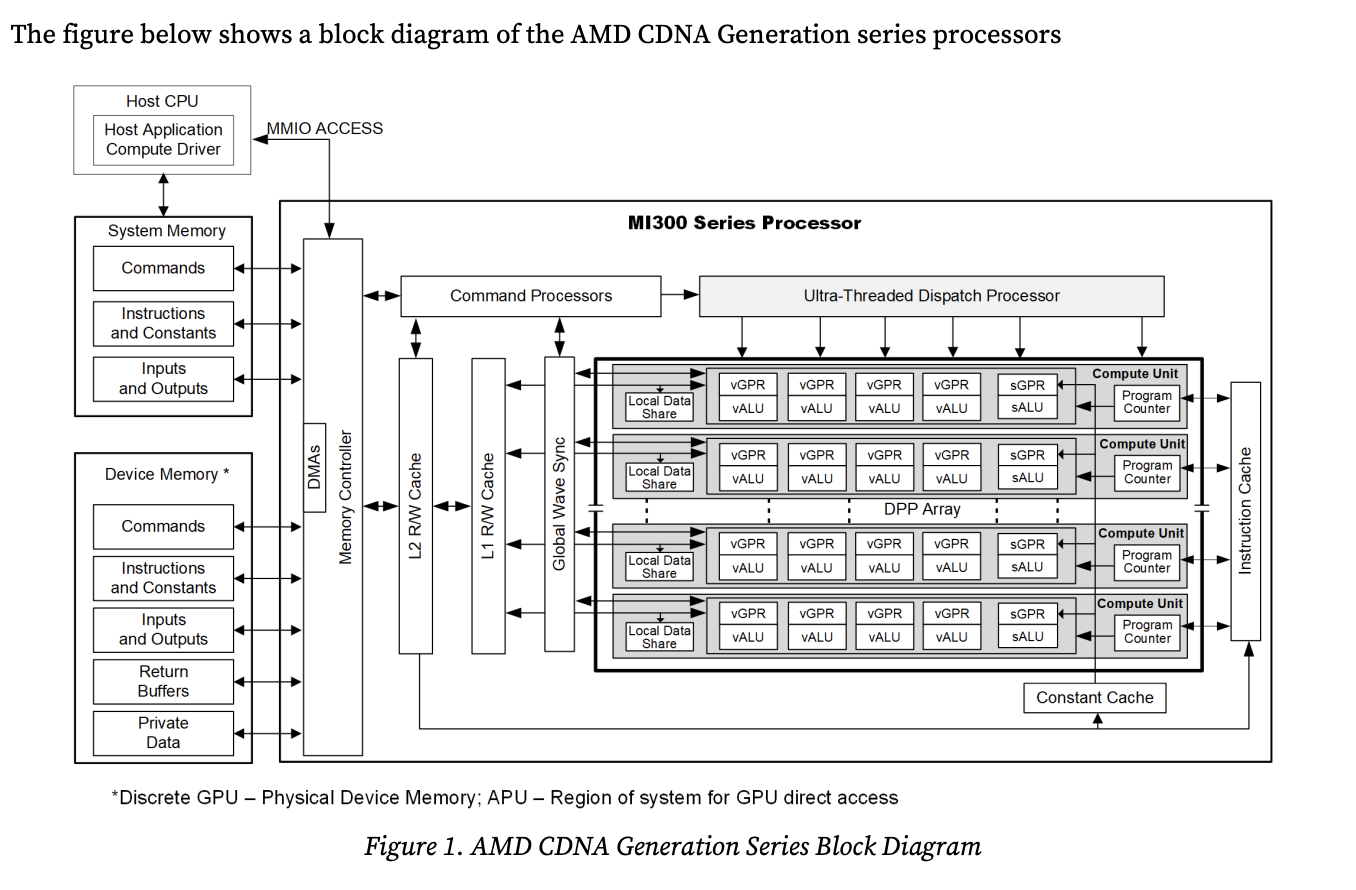
Matrix multiplication in the MI300X GPU is performed by mapping the GEMM operation to the CDNA architecture, which is composed of multiple compute units (CUs) that work in parallel. The matrix multiplication is divided into smaller tiles, which are then processed by the CUs. The core operation performed by each CU is a Matrix fused-multiply-add (MFMA) operation, which computes the product of two matrices and adds the result to a third matrix, each of which is stored in the CU’s register file. The V_MFMA_F32_BF16_BF16 instruction performs a matrix multiplication of two bfloat16 matrices and accumulates the result into a float32 matrix.

The MI300X GPU is composed of 4 CDNA chiplets, each of which contains 76 CUs, each of whcih containers 4 matrix cores. The chiplets are connected to each other using Infinity Fabric links. The chiplets are connected to 2 HBM3 stacks each, creating NUMA (Non-Uniform Memory Access) regions.
Bfloat16 Format
Bfloat16 is a 16-bit floating point format that is designed to provide a good balance between performance and numerical stability. It has the same exponent range as float32, but only 7 bits of precision in the mantissa. This means that it can represent a wide range of values, but with less precision than float32. The bfloat16 format is commonly used in deep learning applications, particularly for training and inference of large language models (LLMs). It allows for efficient computation while maintaining numerical stability, as the exponent range is sufficient to represent the values typically encountered in deep learning workloads.
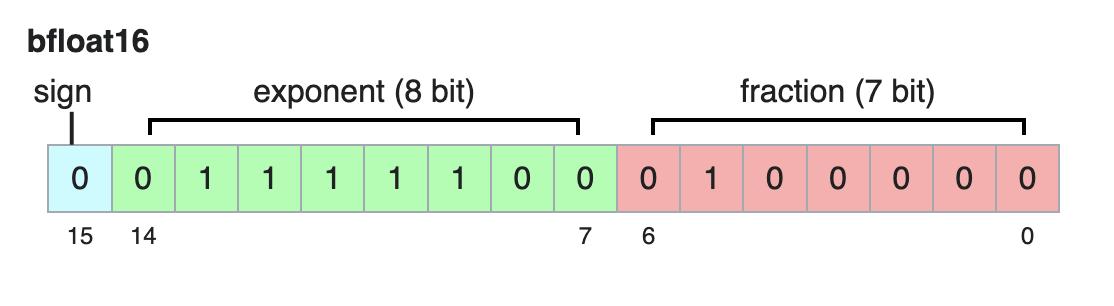
The exponent is stored in 8 bits, with the lowest representable value being -126 and the highest representable value being 127. Accumulation is performed in float32, which allows for higher precision in the final result. During mixed precision training, the weights and input activations are typically cast to bfloat16 before performing the GEMM operation. In particular, a common value of 1.0f corresponds to an exponent of 127 in bfloat16, or in hex 0x7f00, where all bits of the exponent are set to 1.
Benchmark Results
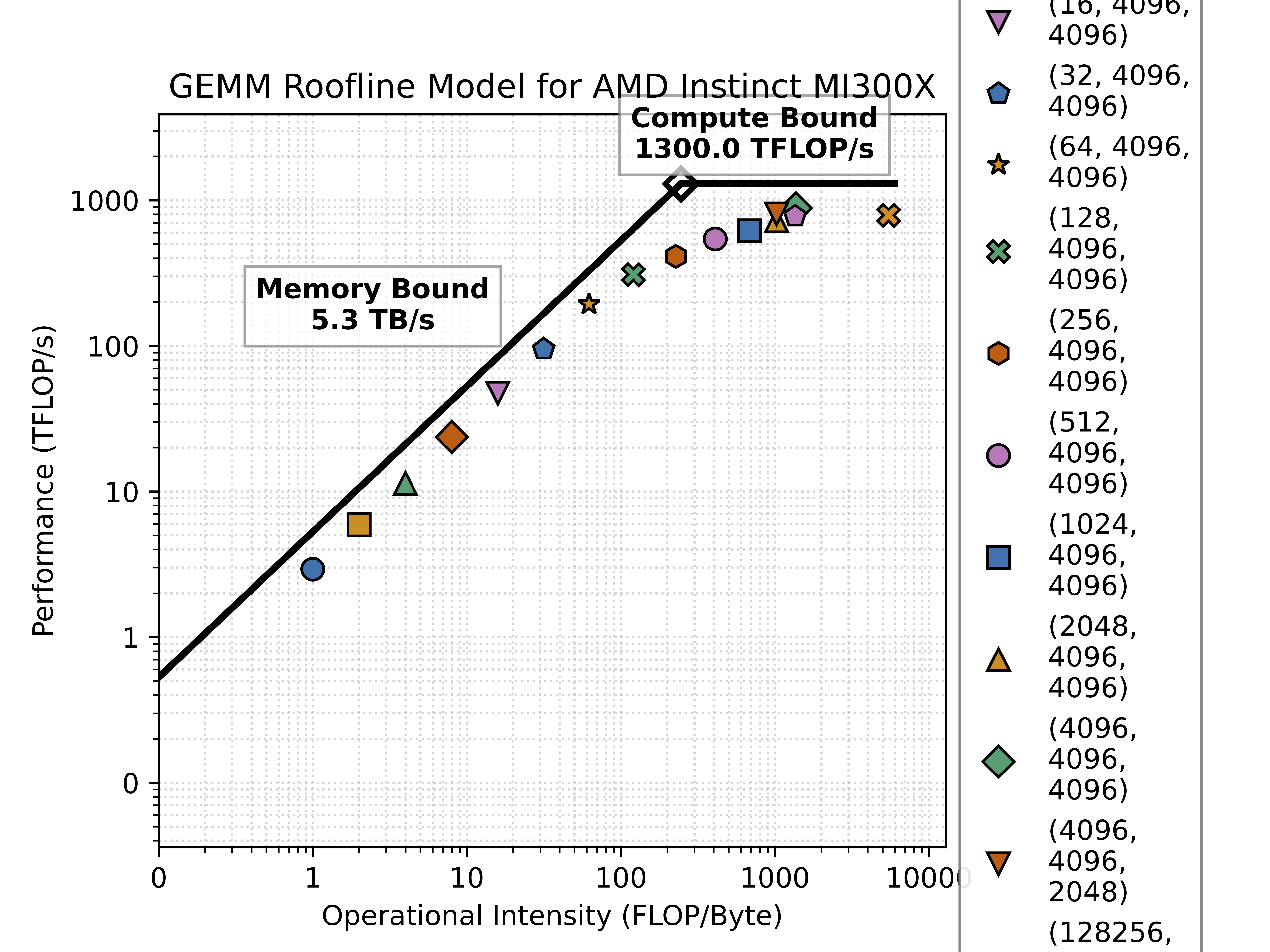
The benchmark results show that the MI300X achieves a peak performance of 890 TFLOP/s for bfloat16 GEMM operations, which is 68.4% of the theoretical peak performance of 1.3 PFLOP/s. MI300X has a power limit of 750W, which becomes the limiting factor for the performance of compute intensive operations like GEMM.
The power consumption of the MI300X during the benchmark is maxed out at 750W. During the most power intensive benchmark, with a large GEMM operation with random bits, the CU clocks are scaled down to 1.1 GHz to stay within the power limit.
Best performance is achieved with a compute intensity of 1365 flops/byte for square 4k by 4k matrices, which is significantly higher than the theoretical minimum of 490 flops/byte.
The number of zeros matters
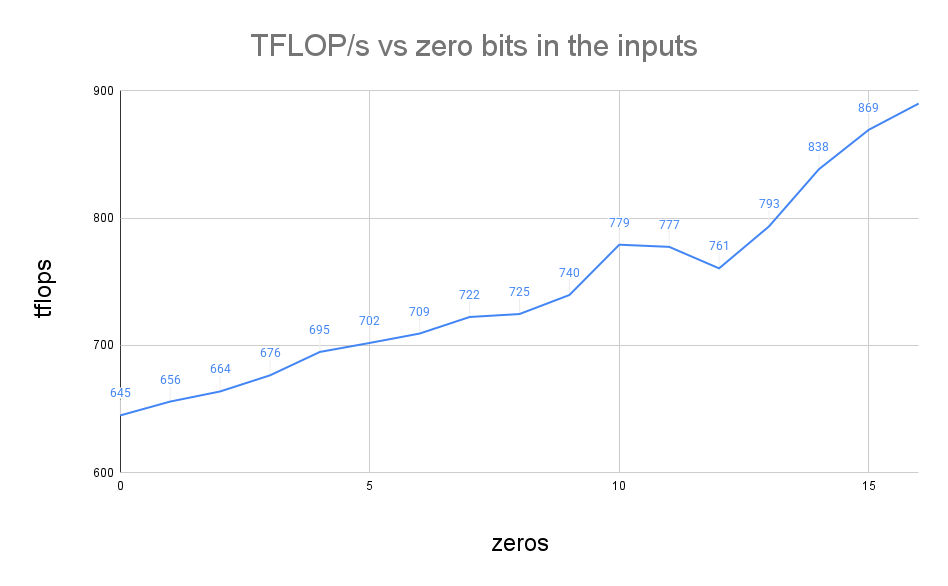
In this figure we sweep the number of zero bits in the input matrices to see how it affects the performance of the GEMM operation. If the inputs are random normally distributed, the performance is 645 TFLOP/s. If the inputs are all zeros, the performance in increases to 890 TFLOP/s. Importantly, for common values from a function like torch.randn with magnitudes between 0.1f and 1.0f, the exponent has 6 or 7 bits set to one because the exponent is stored in two’s complement format. If we scale the numbers down by a factor of 2^-119, we can cut the average number of exponents bits set to one down to 2. This results in a performance of 780 TFLOP/s. This suggests that a huge speedup of 1.37x is possible by paying close attention to the distribution of weight, activation, and delta values in the input matrices.
Analysis
Most practical workloads, especially inference scenarios with small batch sizes, operate in the steep memory-bound region where performance scales linearly with operational intensity. The data points clustering around 10-100 FLOP/byte represent typical LLM inference scenarios, where the MI300X delivers only 5-100 TFLOP/s—far below its theoretical peak. This suggests that batching is incredibly important for achieving high inference performance on the MI300X, especially for requests with large numbers of output tokens.
PyTorch Benchmark Code
You can find the benchmark code on the ScalarLM GEMM Github.
Let’s take a look at the code:
GEMM Sizes
llama_8b_sizes = [
(1, 4096, 4096),
(2, 4096, 4096),
(4, 4096, 4096),
(8, 4096, 4096),
(16, 4096, 4096),
(32, 4096, 4096),
(64, 4096, 4096),
(128, 4096, 4096),
(256, 4096, 4096),
(512, 4096, 4096),
(1024, 4096, 4096),
(2048, 4096, 4096),
(4096, 4096, 4096),
(4096, 4096, 2048),
(128256, 4096, 2048),
(2048, 4096, 14336),
(16384, 16384, 16384),
]
This code sets up the sizes of the GEMM operations to be benchmarked. The sizes are tuples of the form
(m, n, k), where m is the number of rows in the first matrix, n is the number of columns in the second matrix,
and k is the number of columns in the first matrix (or rows in the second matrix). The sizes are chosen to be
representative of the sizes of the matrices used in the Llama 3 8B model. The sizes range from small matrices
(1x4096) to large matrices (4096x4096), with some intermediate sizes. The largest size is 128256x4096, which is
the size of the embedding table in the Llama 3 8B model. The sizes are chosen to be powers of 2, which is a common
practice in deep learning to optimize memory access patterns and performance on GPUs.
Benchmark Setup
Next, we set up the benchmark:
def run_gemm_benchmark():
warmup()
results = {}
for size in tqdm(gemm_sizes):
results[str(size)] = run_gemm(size)
return results
This function runs the GEMM benchmark. It first warms up the GPU by running a few iterations of the GEMM kernel
without measuring the time. This is done to ensure that the GPU is in a good state before running the benchmark. The
function then runs the GEMM kernel for each size in the gemm_sizes list and measures the time taken to perform the
GEMM operation.
Warmup
Warmup is pretty simple.
def warmup():
run_gemm((256, 256, 2048))
global gemm_sizes
gemm_sizes = select_appropriate_size_for_this_machine()
This function runs the GEMM kernel with a size of 256x256x2048 to warm up the GPU. This is a small size that is
sufficient to warm up the GPU without taking too long. The function also sets the gemm_sizes variable to the
appropriate sizes for the current machine. The select_appropriate_size_for_this_machine function is used to
select the appropriate sizes based on how long it takes to run.
Running GEMM PyTorch
The run_gemm function is where the actual GEMM kernel is run. It uses PyTorch to allocate memory on the GPU and
perform the matrix multiplication. The function measures the time taken to perform the GEMM operation and calculates
the performance metrics such as FLOPS, bytes transferred, and operational intensity.
The function uses PyTorch’s matmul method to perform the matrix multiplication. The out parameter is used to specify
the output tensor where the result of the multiplication will be stored. This is more efficient than creating a new tensor
for the result because it avoids allocating memory for the result tensor. The function also uses PyTorch’s CUDA events
to measure the time taken to execute the kernel. CUDA events are used to measure the time taken to execute a kernel on
the GPU. The record method is used to record the time at which the event is recorded, and the elapsed_time method
is used to calculate the time taken to execute the kernel. The time is measured in milliseconds, so we multiply by
1e-3 to convert to seconds. Using events is necessary because the GPU is asynchronous, meaning that the CPU and GPU can
run in parallel. The CPU can continue executing while the GPU is performing the matrix multiplication. This can lead to
misleading results if the time taken to execute the kernel is not measured correctly.
def run_gemm(size):
m, n, k = size
#a = torch.randint(0, 1, (m, k), dtype=gemm_dtype, device=get_device())
#b = torch.randn(k, n, dtype=gemm_dtype, device=get_device()) * torch.randint(0, 1, (k, n), dtype=gemm_dtype, device=get_device())
#b = torch.randint(0, 1, (k, n), dtype=gemm_dtype, device=get_device())
a = make_random(m, k, 8, 8, 2**-119) #torch.randn(m, k, dtype=gemm_dtype, device=get_device())
b = make_random(n, k, 8, 8, 2**-119) #torch.randn(n, k, dtype=gemm_dtype, device=get_device())
c = torch.zeros(m, n, dtype=gemm_dtype, device=get_device())
# run at least 3 seconds
start_time = time.time()
end_time = start_time + 3
barrier()
start = get_event()
end = get_event()
start.record()
iterations = 0
while time.time() < end_time:
torch.matmul(a, b.T, out=c)
iterations += 1
end.record()
iterations = max(1, iterations)
barrier()
seconds = start.elapsed_time(end) / 1000 / iterations
return {
"size": size,
"time": seconds,
"flops": 2 * m * n * k,
"flop/s": 2 * m * n * k / seconds,
"bytes": (m * k + k * n + m * n) * 2,
"operational_intensity": 2 * m * n * k / ((m * k + k * n + m * n) * 2),
"GFLOP/s": 2 * m * n * k / seconds / 1e9,
}
Handling GPUs
When running on a GPU, the benchmark uses PyTorch’s CUDA events to measure the time taken to copy the data. CUDA events are
used to measure the time taken to execute a kernel on the GPU. The record method is used to record the time at which
the event is recorded. The elapsed_time method is used to calculate the time taken to execute the kernel. The time
is measured in milliseconds, so we multiply by 1e-3 to convert to seconds. Using events is necessary because the GPU
is asynchronous, meaning that the CPU and GPU can run in parallel. The CPU can continue executing while the GPU is
copying data. This can lead to misleading results if the time taken to copy the data is not measured correctly.
In order to make the code cross-platform, we define a get_event function that returns a CUDA event if the GPU is available, or a CPU event
if the GPU is not available. The CPU event is a simple wrapper around the time module that records the time when the event is created and
calculates the elapsed time between two events.
class CPUEvent:
def __init__(self):
self.time = 0
def record(self):
self.time = time.time()
def elapsed_time(self, other):
return (other.time - self.time) * 1000
def get_event():
if torch.cuda.is_available():
return torch.cuda.Event(enable_timing=True)
else:
return CPUEvent()
def barrier():
if torch.cuda.is_available():
torch.cuda.synchronize()
else:
pass
def get_device():
if torch.cuda.is_available():
return torch.device("cuda:0")
else:
return torch.device("cpu")
Selecting the appropriate size for the machine
The select_appropriate_size_for_this_machine function is used to select the appropriate sizes for the GEMM operations
based on the performance of a small GEMM operation. The function runs a small GEMM operation with a size of 256x256x2048
and measures the time taken to perform the operation. It then calculates the performance metrics such as FLOPS, bytes transferred,
and operational intensity. The function then calculates the time it would take to run each of the Llama model sizes based
on the performance of the small GEMM operation.
def select_appropriate_size_for_this_machine():
# Try a small GEMM, and time it
# If it runs too fast, select a bigger model
# If it runs too slow, select a smaller model
tiny_gemm = (256, 256, 2048)
metrics = run_gemm(tiny_gemm)
# Get the total number of flops in each model
def get_flops(size):
m, n, k = size
return 2 * m * n * k
tiny_flops = get_flops(tiny_gemm)
logger.info(f"Tiny GEMM took {metrics['time']} seconds it ran at {metrics['GFLOP/s']} GFLOP/s")
# get the flops for each llama model
llama_100m_flops = sum([get_flops(size) for size in llama_100m_sizes])
llama_1b_flops = sum([get_flops(size) for size in llama_1b_sizes])
llama_8b_flops = sum([get_flops(size) for size in llama_8b_sizes])
# Get the time it took to run the tiny gemm
tiny_time = metrics["time"]
# Get the time it would take to run each llama model
llama_100m_time = llama_100m_flops / tiny_flops * tiny_time
llama_1b_time = llama_1b_flops / tiny_flops * tiny_time
llama_8b_time = llama_8b_flops / tiny_flops * tiny_time
logger.info(f"GEMM from llama_100m will take {llama_100m_time} seconds")
logger.info(f"GEMM from llama_1b will take {llama_1b_time} seconds")
logger.info(f"GEMM from llama_8b will take {llama_8b_time} seconds")
# Select the largest model that will take at most 10 seconds to run
if llama_8b_time < 10:
return llama_8b_sizes
elif llama_1b_time < 10:
return llama_1b_sizes
elif llama_100m_time < 10:
return llama_100m_sizes
else:
return [tiny_gemm]