Tokenformer: A Scalable Transformer Architecture
Background
Transformers, which form the backbone of most foundation models, face significant challenges when it comes to scaling. This is primarily due to their reliance on a set number of parameters within linear projections. When changes are made to the architecture, such as adjusting channel dimensions, it typically necessitates retraining the entire model from the beginning. This becomes increasingly problematic as models grow larger, as the computational costs associated with retraining become prohibitively expensive and unsustainable.
To address these scaling issues, a new architecture called Tokenformer has been developed. Tokenformer is a fully attention-based model that expands upon the traditional use of attention mechanisms. In addition to using attention for computations between input tokens, Tokenformer also applies attention to the interactions between tokens and the model’s parameters.
The key innovation of Tokenformer lies in its treatment of model parameters as if they were tokens themselves. This approach allows for the replacement of all linear projections found in traditional Transformers with a novel token-parameter attention layer. In this layer, the input tokens function as queries, while the model parameters serve as keys and values.
This reformulation of the Transformer architecture offers a significant advantage: it enables the model to be scaled up progressively and efficiently without the need for complete retraining from scratch. This ability to scale without full retraining represents a major step forward in addressing the computational challenges associated with developing and expanding large language models.
To apply tokenformer to a model in , we follow an approach similar to LoRA (Low-Rank Adaptation) where token-parameter attention layers are added in parallel to the existing attention layers. This allows for the model to be incrementally scaled up without the need for full retraining. The number of parameters in the key-value pairs can be adjusted after training to control the model’s capacity and performance.
Tokenformer is an innovative, fully attention-based architecture that addresses scaling challenges in traditional Transformers:
- Replaces linear projections with token-parameter attention layers
- Treats model parameters as tokens, with input tokens as queries and parameters as keys/values
- Enables incremental scaling without full retraining
- Functions as an extreme Mixture of Experts (MoE) model
- Facilitates efficient parameter tuning for new tasks
Key advantages:
- Progressive scaling from 124M to 1.4B parameters and beyond
- Performance comparable to full retraining
- Over 50% reduction in training costs
Tokenformer preserves inter-token computations while extending the Transformer architecture, offering a more flexible and efficient approach to large language model development.
LoRA (Low-Rank Adaptation) versus Tokenformer
Tokenformer and LoRA are two different approaches for adapting large language models (LLMs).
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning method that adds small trainable rank decomposition matrices to existing weights. It freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the transformer architecture. This approach significantly reduces the number of trainable parameters while maintaining performance comparable to full training.
In contrast, Tokenformer is a more recent development that only leverages the attention mechanism for both input token computations and token-parameter interactions. This reformulation results in a natively scalable architecture, allowing for progressive and efficient scaling.
In summary, while both methods aim to improve LLM adaptation, LoRA focuses on parameter efficiency and versatility, while Tokenformer prioritizes flexibility and scalability. The key advantage of Tokenformer is its ability to scale up models without full retraining, or the need to keep adding new LoRA adaptors to increase capacity.
Our Implementation
is a unified framework for training and inference of language models. Its primary objective is to seamlessly support novel modeling techniques across both training and inference phases. The framework’s inference engine is based on vLLM, which imposes certain constraints on achieving this unified approach. This discussion outlines the implementation strategy for integrating Tokenformer into ScalarLM and provides specific details for both training and inference processes.
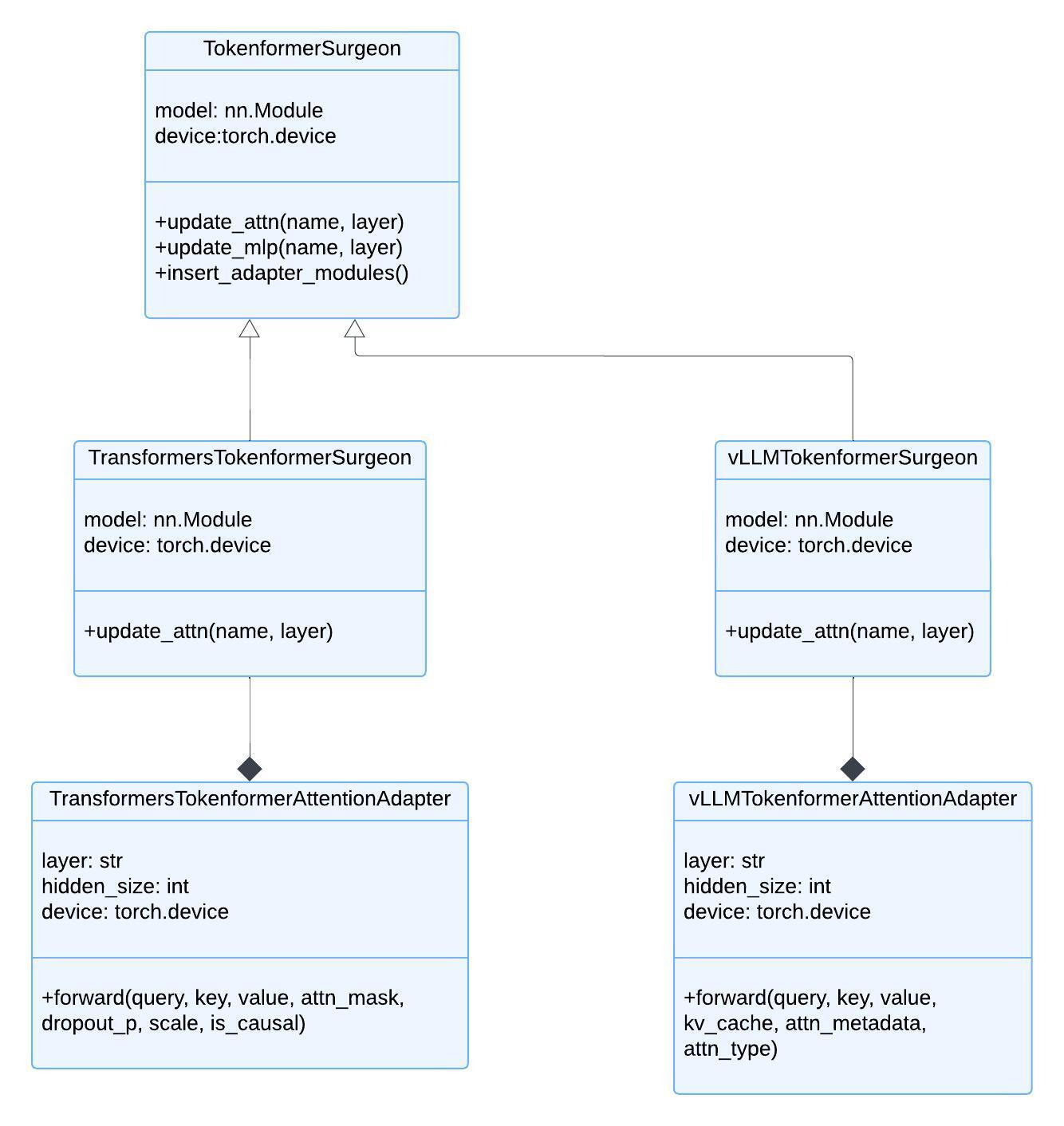
Tokenformer’s architecture requires the integration of cross-attention based adapters to either the feed-forward (MLP) layers, the existing attention layers, or both. To accomplish this, a visitor pattern is implemented. This pattern, implemented by the TokenformerSurgeon class, traverses the underlying PyTorch graph, identifying MLP and attention layers within any given model network and wrapping them with Tokenformer adapters.
The current implementation of Tokenformer in specifically targets Llama-based models.
Training with Tokenformer
The implementation of Llama models in the HuggingFace transformers library presents a challenge for the visitor strategy. This is because attention layers are not always encapsulated as separate modules. Instead, the library often utilizes torch.nn.functional attention mechanisms, such as scaled_dot_product_attention, within encompassing modules.
To address this issue, the implementation extends the HuggingFace transformers Llama library. This extension encapsulates attention mechanisms into their own module classes, thereby enabling the seamless application of the visitor pattern.
vLLM Inference with Tokenformer
vLLM, the basis for ‘s inference engine, does not rely on HuggingFace’s transformers implementations for many of its models. Instead, it provides its own implementations in the vllm/model_executor/models directory.
This architectural difference creates an incompatibility between vLLM and HuggingFace transformers. As a result, separate Tokenformer adapters were implemented for vLLM and HuggingFace transformers. These distinct implementations are necessary due to the different APIs for forward calls that need to be supported.
The implementation details are visually represented in a UML diagram, which illustrates the relationships and structures of the components involved in supporting Tokenformer within the framework.
Conclusion
Tokenformer introduces a naturally scalable architecture that leverages the attention mechanism to facilitate not only inter-token computations but also interactions between tokens and model parameters, thereby enhancing architectural flexibility. By representing model parameters as tokens, we can replace all linear projection layers in the Transformer with attention layers, allowing for seamless and efficient incremental scaling without the need for retraining from scratch. This architecture offers greater flexibility than traditional Transformers and will further contribute to the development of foundation models.